Navigation Bar

BLOG
COMPANY
DOCS
Evaluation Metrics from Ragas
In today's data-driven landscape, industries like financial services rely heavily on precise and efficient information extraction from documents, especially those containing both unstructured text and structured data like tables and charts. Traditional Optical Character Recognition (OCR) models, despite their widespread use, often fall short in handling complex document formats, leading to suboptimal performance in advanced AI applications. Recognizing this gap, CambioML and Epsilla have introduced a cutting-edge knowledge retrieval system that promises to significantly enhance accuracy and recall in data extraction tasks.
OCR-based models, while effective at detecting text, struggle with extracting layout information and accurately pulling data from tables and charts. These limitations become particularly apparent in industries where precision is paramount, such as finance and healthcare. To address these challenges, CambioML and Epsilla have developed a novel approach that integrates state-of-the-art table extraction models with Retrieval-Augmented Generation (RAG) techniques. This new system achieves up to 2x precision and 2.5x recall compared to conventional RAG systems, setting a new standard for document question answering.
At the heart of this breakthrough is AnyParser, a model powered by advanced vision language models (VLMs) that excels in extracting information from diverse data sources. Unlike traditional models that rely heavily on OCR, AnyParser uses a combination of visual and text-based encoders to capture even the smallest details from documents, ensuring that no critical data is missed. This approach is particularly beneficial in extracting high-resolution data from financial and medical documents, where accuracy is critical.
Complementing AnyParser is Epsilla, a no-code RAG-as-a-Service platform designed to optimize various RAG pipelines. Epsilla enhances the knowledge retrieval process through advanced chunking, indexing, and query refinement techniques. By integrating keyword-based and semantic search methods, Epsilla delivers highly accurate and contextually relevant results, making it an ideal solution for large language model (LLM) applications.
Evaluation Metrics from Ragas
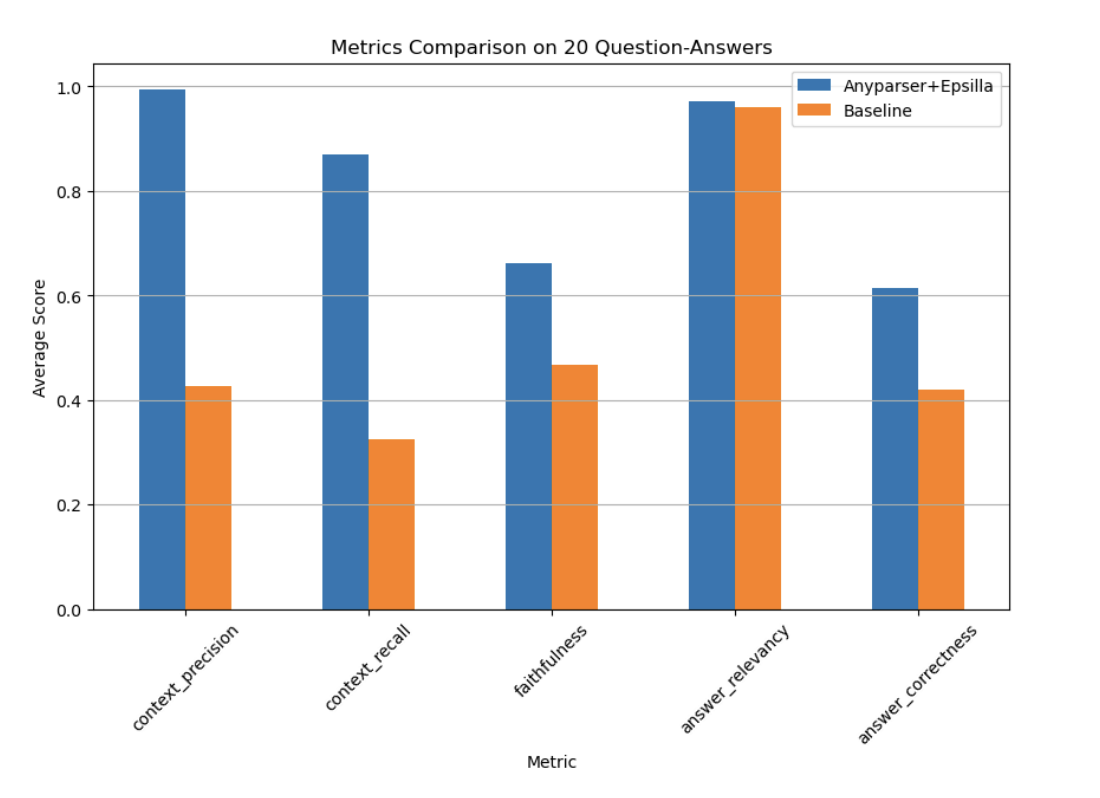
To validate the effectiveness of AnyParser and Epsilla, the system was tested on 10-K financial documents from companies like Apple and Meta. The results were impressive, with the system demonstrating significantly higher performance across all key evaluation metrics, including context precision, recall, faithfulness, and answer correctness. In some cases, the system outperformed traditional RAG systems by as much as 2.7x, highlighting its superiority in handling complex data extraction tasks.
The introduction of AnyParser and Epsilla marks a significant advancement in knowledge retrieval technology. By combining advanced extraction models with a robust RAG infrastructure, this integrated solution not only improves accuracy and efficiency but also offers the flexibility and privacy that modern enterprises demand. As technology continues to evolve, the applications and benefits of this system are vast and promising, making it a game-changer for industries that depend on precise data extraction.
For the full detailed whitepaper, please check out this link.



